修正が完了し、全テストも通った。晴れて wasavi は beyond BMP enabled になった。
Handling Unicode #12
Reply

修正が完了し、全テストも通った。晴れて wasavi は beyond BMP enabled になった。
様々な箇所で必要なら Unistring を使用するようにする修正が完了しつつある。実際には Buffer クラスの他、様々な箇所で Position クラスの col プロパティを直接インクリメント・デクリメントしており、それを修正していくことになる。
このアプローチはつまり、基本的には文字列が UTF-16 のシーケンスであることを意識した上で、各箇所で論理的な文字単位と UTF-16 のインデックスとを相互変換するということで、割と煩雑だ。
一方、異なるアプローチも考えられる。文字のインデックスは常に論理的な文字単位をベースにし、Buffer クラス内でレンダリングする際に Unistring を使う。おそらくは、こちらが正しい。ただ現在はレンダリングはブラウザ任せなので、やりたいけどそうはいかない。これは将来の課題だ。
ところで javascript で構築した vi という点でいろいろな人が作った諸々を見てみると、おそらくサロゲートペアと結合文字列を意識した動作をするものはない。たとえば CodeMirror の vim バインディングはなかなか良く出来ているが、上記のトピックを正しく処理しない。その点で wasavi のアドバンテージが 1 つ増えたわけで、これは誇っていいと思う。
他のモーションも修正する。
とりあえず vim に合わせてみる。
その他、モーション以外に編集コマンド、bound モード、line_input モードが残っている。なかなか先は長い。
[cci]motionUpDown[/cci]。
テキストエディタはカーソルの行位置・桁位置を管理保持する。このとき桁位置に関して、メモ帳のようなシンプルなエディタ以外はたいてい、カーソルの本来の桁位置とは別に架空の桁位置を持っている。この架空の桁位置は、カーソルが水平移動した時にカーソルの本来の桁位置に同期する。カーソルが垂直移動した時は変更されず、かつカーソルの桁位置は架空の桁位置に最も近い位置に算出される。
これで何が良くなるのかというと:
aaaaaaaaaaa
bbbbbbbbbbb
なんてテキストの先頭行の最終桁にカーソルがあった時、最終行の最終桁近辺を編集したくなったとする。そこで、下矢印キーを 2 回押すわけだが。架空の桁位置がないと中間の行でカーソル位置が行頭に固定されてしまい、最終行に達した時にはわざわざ最終桁へ移動させる手間が増えてしまう。架空の桁位置の仕組みがあると、最終行にカーソルが移動した時その桁位置は架空の桁位置に最も近い位置に再生されて、無駄なカーソル移動をしなくて済むというわけだ。このとき、絶対に等幅のフォントでしか描画しない!というわけでなければ、架空の桁位置はピクセル単位で保持することになる。そういうわけで、「あるピクセル位置に最も近い、文字列上の桁位置」というのを算出する処理が必要になる。
処理の内容は、素朴に考えれば、文字列の先頭から1文字ずつ切り出すループを設け、その部分文字列の offsetWidth を出し、それが基準ピクセル位置を超えていたならば、超える直前の offsetWidth と比較して距離が近い方を採用し、それに対応するループカウンタが結果の桁位置になる……という感じになる。
しかしこのまま組むと結構遅い。offsetWidth というのはそんなに軽くないメソッドなので、100 文字あったら 100 回 offsetWidth を呼ぶというのは避けなければならない。
で、実は [cci]motionUpDown()[/cci] はすでにそうなっていて(offsetWidth の呼び出しが算出される桁位置の log2 〜 2log2 で収まるようになっている)、それを Unistring を使うように修正する必要があり、そうした。
この修正は、折り返し行単位でのカーソルの上下移動とも関わるのでこれで終わりではない。
* * *
そういうわけで、その辺の諸々を更新。
次に、[cci]f/F/t/T[/cci] コマンド。つまり [cci]motionNextWord()[/cci] と [cci]motionPrevWord()[/cci]。
これらのコマンドの本質的な部分では、特に書記素クラスタなどのことを考える必要は実はあまりない。キーボードから直接入力できる文字の中に結合文字が基本的にない。OS の digraph 機構等々を経由してもし入力できたとしても、コマンドは書記素クラスタの先頭文字との一致を判定するので、結合文字そのものにマッチすることがない。
これは不便といえば不便かもしれない。「Circumflex 付きの任意の文字をサーチしたい」などといった要件はないわけではないと思う。でもそういうのは [cci]/ ?[/cci] コマンドが担当するべきかなあ。微妙。
ただ、[cci]t/T[/cci] コマンドは入力された文字の位置へカーソルをおいた後 1 文字進めたり戻ったりする仕様なので、その時は 1 書記素クラス多分前後させねばならない。
次に、[cci]^/$[/cci] コマンド、つまり [cci]motionLineStart()[/cci] と [cci]motionLineEnd()[/cci] だが、これこそ書記素クラスタのことを考える必要は全くない。何を単位にしようが文字列の先頭と末尾は同じだ。
めんどくさいのは [cci]j/k[/cci] すなわち [cci]motionUpDown()[/cci] だ。
順当に行けば、次は [cci]w/W/e/E/b/B[/cci] なのだが、数が多いのでこれが意外と面倒くさい。
これらのコマンドは、Unicode 関連を抜きにしてもいじる必要があった。従来は、カーソルをジャンプさせるべきテキストの切れ目をオンザフライで走査していた。このとき、[cci]w/W/e/E[/cci] なら走査の方向は順方向、[cci]b/B[/cci] なら逆方向なのだが、一部の文字は走査の方向によって切れ目が変化してしまうという問題があった。
従ってオンザフライではなく、一旦常に同一方向でテキストを走査して切れ目を貯めこみ、次にそれを利用するという形にしたかったのだ。そして、「テキストを走査して切れ目を貯めこむ」という処理は UAX #29 で述べられている word boundary そのものなので、ついでにそれにも準拠したいなあということなのであった。
そういうわけで [cci]w/W/e/E/b/B[/cci] コマンドを全て Unistring が切り出した単語の情報を利用するように書き換えた。
ちなみに割とどうでもいいような、それでいて非常に重要なことのようなトピックとして、UAX #29 のルールに則ると濁点・半濁点付きの半角カナにおいてそれらの 2 文字(UTF-16 単位で)が 1 つの書記素クラスタとして扱われるというものがある。従ってカーソルが濁点・半濁点だけを指すということがなくなるし、また削除するとしたら書記素クラスタ単位になる。これはなかなか目からウロコな仕様で、改めて考えてみるとこちらのほうが確かに自然なのだが、日本産のテキストエディタでこういう動作をするものは多分なかったと思うのですんなり受け入れられるか少し不安な感じはする。
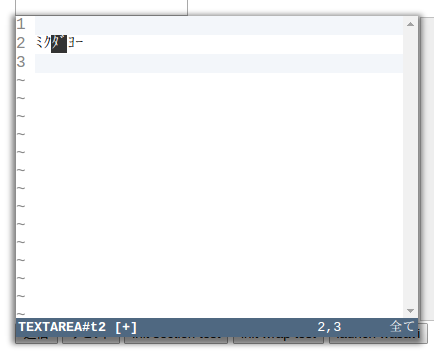
カーソル下の基底の半角カナと付随する濁点とがまとめて反転する
そういうわけでぼちぼちと wasavi に組み込み始める。
まずは簡単そうな [cci]motionLeft()[/cci] からとりかかってみよう。
function motionLeft (c, count) {
// カウントの値を正規化
count || (count = 1);
// 現在のカーソル位置
var n = buffer.selectionStart;
// 現在行の書記素クラスタ群
var clusters = getGraphemeClusters(n);
// カーソルが位置する書記素クラスタのインデックス
var clusterIndex = clusters.getClusterIndexFromUTF16Index(n.col);
// 移動できないならメッセージを生成
if (c != '' && clusterIndex <= 0) {
requestNotice({silent:_('Top of line.')});
}
// 書記素クラスタ単位でカウント分戻る
// ただし、0 未満にはしない
if (clusters.length) {
n.col = clusters.rawIndexAt(Math.max(
clusterIndex - count, 0));
}
// バッファのカーソル位置に上書き
buffer.selectionStart = n;
// キー名をコマンド列に追加
prefixInput.motion = c;
// 水平移動なので、"記憶された水平位置" は更新する必要がある
invalidateIdealWidthPixels();
// コマンド実行完了
return true;
}
とこんなように Unicode のめんどくさい部分は全て Unistring が面倒を見てくれる。
GraphemeBreakProperty.txt、WordBreakProperty.txt、Scripts.txt から生成するデータの 1 エントリに従来 8 バイトを割いていたのを、5 バイトまで詰めてみた。
ただ、これで最適だというわけではない。npmjs.com 上のライブラリ grapheme-breaker では Trie 木の構造で GraphemeBreakProperty データを保持していて、そのサイズは約 3KB だ。同じデータが Unistring では約 6KB。すごい。
それはそれとして、そろそろ wasavi に組み込んでみたい。
やはり、漢字やタイ語云々についてはルールの中に組み入れるのはやめ、
場合には分割しないようにした。この拡張ルールは [cci]Unistring.getWords(str, useScripts)[/cci] の第 2 引数で有効にするかを指定できる。
それから、UAX#29 のルールだと、空白類を1文字ずつ分割してしまう。これはそういうようにデザインされているのかわからないが、wasavi に組み込むにあたってはとても不便そうだ。そういうわけで連続する空白類はひとまとまりの擬似的な単語として扱うようにした。
ちなみに Scripts.txt 併用ルールだと、連続する絵文字はひとまとめに扱われない。絵文字は Common スクリプトに含まれるからだ。でも、たとえば Chrome や Firefox で Ctrl+← や Ctrl+→ 使うとひとまとめにしてるんだよね。どうしようかな。
unistring に、UAX#29 における word boundary の定義に従って文字列を単語で分割するメソッドを追加したい。
そういうわけでやってみたところ、UAX#29 自身に書いてあることであるが、ドキュメントに例示されているアルゴリズムそのままだと、あまり実用にはならない。とてもありがちなことに、ラテン文字が処理のメインになっているのだ。なぜかカタカナだけは組み入れられているが……。ただこれは無理もないことで、日本語と中国語の場合は分かち書きをしないので単純なルールで分割することはできない。Mecab みたいな形態素解析プログラムの助けを借りなければならない。
しかしまあだとしても、例えばひらがなが1文字ずつ分割されたりするのは実際実用にならないわけで、ちょっとだけ拡張したい。
できれば実装自体は UAX#29 通りにして、分割のルールを独自に追加変更できるようなインターフェースを組み込もうかと思ったが、面倒そうなのでやめた。とりあえず UAX#29 で例示されているタイ語、ラオス語、クメール語、ミャンマー語、それから漢字とひらがなについて分割を禁止するようなルールを組み込んだ。ただこの辺はこれらのスクリプトに限定せず、WB14(なんでも分割可のルール)の直前に、同一スクリプト間は分割禁止、みたいなルールを追加するなど、ある程度一般化したほうがよいかもしれない。
そんなわけで WordBreakTest.txt の1489種のテストに全てパスするようになった。ちなみに書記素クラスタの方も GraphemeClusterTest.txt の402種のテストに全てパスする。