
UFO updated to 1.0.22
Reply

前の記事の続き。
という問題。
まず、ambiguous な方は、UFO 側のグリフを 1 カラム分で統一するようにほとんどすべて書き直した。これはつまり、●とか◎とかの日本古来の(?)全角文字が UFO においては半角分の幅のちっこい丸で表示されるということを意味する。これはなかなか反感を食らいそうな決定ではあるのだけど、でもねえギリシャアルファベットやキリルアルファベットを始めとして、本質的に 1 カラム分のグリフで扱ったほうが収まりがいい字が 2 カラム分のそれの、ざっくり 4 倍くらいあるんですよ。
ちなみにそういうわけなので、UFO を使用する際は vim の ambiwidth は single にしないといけない。
neutral な方は、フォント側ではいかんともしがたいので知らないふりをする。こちらもそれぞれのグリフを 1 カラム分に書きなおすことができれば、それはそれでひとつの解決策ではあるので、ためしに Devanagari でやってみたのだが、えー、まあ、無理です。ちっこすぎて目が悪くなる。
くわえて Devanagari 特有の合成処理が、(xfce-terminal では)なんか動いているような動いてないような、vim 側の問題のようなそうでないような、微妙な感じなのでそのへんも含めてやはりフォント側で頑張ってどうこうなる問題ではないと思う。
うーん、これはどうなんだろうか。もしかしたら、端末エミュレータと、込み入った Unicode 文字の処理というのは、想像以上に食い合わせが悪い関係なのかもしれない。実用に即していないおかしな仕様を、これまた中途半端に摩訶不思議な実装をしたまま、誰もそれをどううまく直せばいいのかわからないという。
いやーまさかそんなことはないんだよね……?
UAX#11: East Asian Width という、なんとも適当なドキュメントがある。
いわゆる全角・半角という概念を Unicode 上に持ってきて、どの文字が Wide でどの文字が Narrow か云々、というのを定義してたりしてなかったりする実に適当なドキュメントである。
まず幅についてのクラス分けをしている。
Unicode のすべてのコードポイントにこのクラスのいずれかを割り当てる。それにより、端末のような縦横のグリッドの中に文字を収めていくような表示デバイスについて、グリッドいくつ分を消費するのかの判断のもとになる、はずだった。Wide/Full width/Narrow/Half width については悩む必要はないのだが、問題は Ambiguous と Neutral なのだ。
Ambiguous な文字の幅の問題は、たとえば vim で「●」とかの表示が変なんですけど! → set ambiwidth=double しなさい的なお約束がググれば出てくるアレである。これについては、Unifont においては更に厄介な問題となっている。
いずれの端末エミュレータにしても、あるいは vim のようにアプリケーション側で Ambiguous な字をハンドリングするにしても、だいたいは A 属性の文字全体を半角として扱うか、それとも全角として扱うかの二者択一になると思う。ところがこれに対して Unifont では、半角のつもりの A 属性の字と全角のつもりのそれが混在しているのだった。たとえば U+2460、丸数字の1は Ambiguous 属性だが、Unifont はこれを全角幅としてデザインしている。一方、U+0391 からの Greek アルファベットもまた Ambiguous であり、そのグリフは半角幅である。
すなわち、端末で Unifont を使っている限り、Ambiguous な字の取り扱いを全角にしようが半角にしようが、その半分は常に正しく表示できない。
なんだこれ。どうしろってんだ。
次に Neutral な文字で、こちらはさらに輪をかけて混沌としている。
ぶっちゃけた話全角・半角の違いって、プロポーショナルフォントを描画できるデバイスとか、描画を自分で完全に制御できるプログラムではそれほど重要ではない。むしろ端末のような表示デバイスで「どう表示するか?」に直結してくる問題だと思うのだけど、冒頭の UAX #11 はどういうわけか端末に対する記述は全くない。「文字を幅によってクラス分けしてみたよ! やったね!」以上のことを何も教えてくれない。
なんとか判断してみるにしても、Neutral はつまるところ Neutral である。幅の情報は一切含んでいない。それを半角・全角のいずれかと判断するためのいずれの理由も見出すことはできない。とりあえず実際のところ、おそらく既存の端末エミュレータはそれを Narrow 文字として取り扱うと思う。それが楽そうなので。
一方、Unifont はどうなっているかというと、たとえば Devanagari の文字はすべて Neutral だが、なんとすべて Wide としてデザインしてあるのである。16 ピクセルでよく描いたなーと思わせる良いグリフなのだけど、しかし以上のような状況を勘案すると、今のところ既存の端末エミュレータの中のテキストエディタ上でそれを正しく表示したり編集したりはできないんじゃないかと思う。
えーと…なんだこれ。どうしろってんだ。
UFO
http://akahuku.github.io/ufo/
Linux 向けの、実用に足る unicode ベースのビットマップフォントが、もしかして未だにないんじゃないのか? という問題を解決したい。
実のところを言えば、unicode ベースのビットマップフォントというのはすでにある。
これは Basic Multilingal Plane の全域をサポートした 8×16/16×16 ドットのビットマップフォントである。
しかしながら、いくつか問題があるのである:
こういうわけで、日常的に端末で使えるかどうかというと微妙なのであった。
一方で、GNU のプロダクトである。グリフの元データとなる hex ファイルや、さまざまなユーティリティプログラムも込ですべてが公開されている。フォークして、これらを元にさせていただきつつ新しいのを作ればよいのではないか。そうだそうだ、そうしよう。
* * *
ということで、新しくグリフをデザインしたり、懐かしの jiskan16 を持ってきたり、東雲フォントをもってきたりいろいろした結果、できた。名前は特に意味はないが、UFO とした。地球のフォントに飽きたところよ。
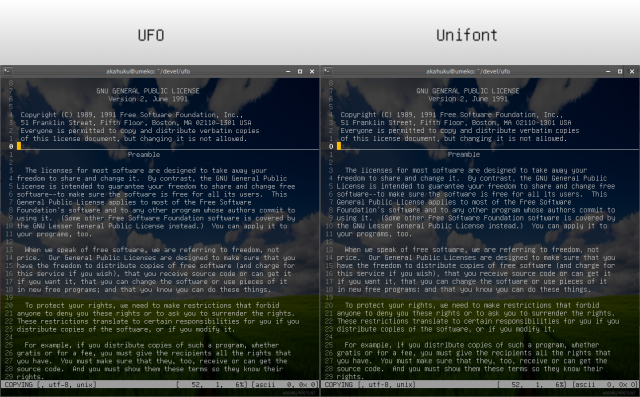
Latin 文字
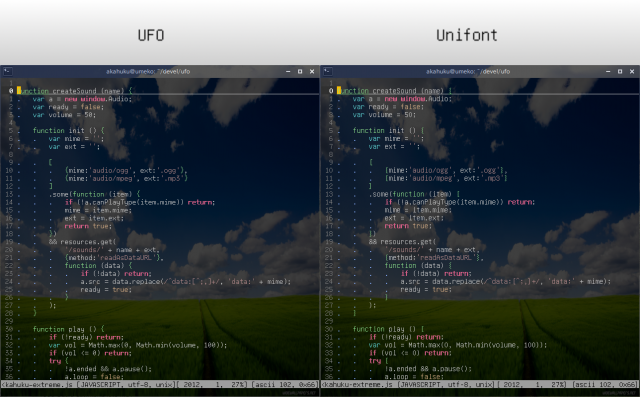
ソースコード
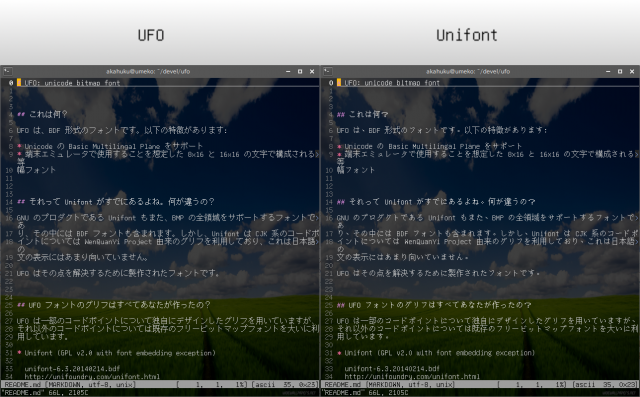
日本語の文
もちろんこれで完成というわけではまったくない。既知の問題として CJK のグリフがバウンディングボックスを目一杯使っているのでスクリーンにぎっしり日本語の文章を表示するとかなり見にくい。もしかしたら CJK グリフは一回り小さい wqy なビットマップフォントから改めて持ってくる必要があるかもしれない。
とりあえず個人的に使ってみつつ微調整したい。