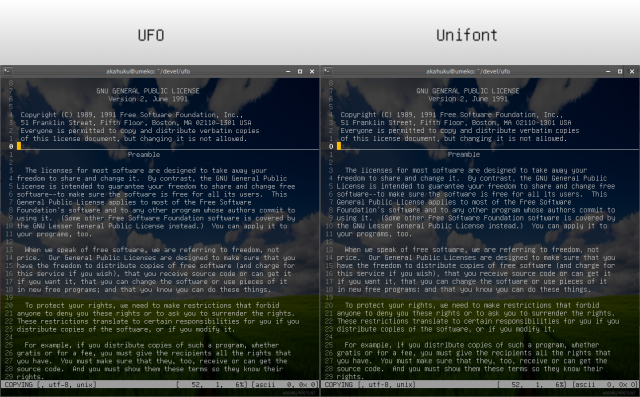
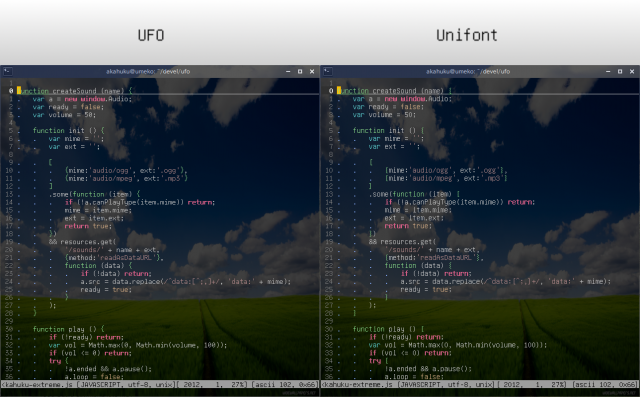
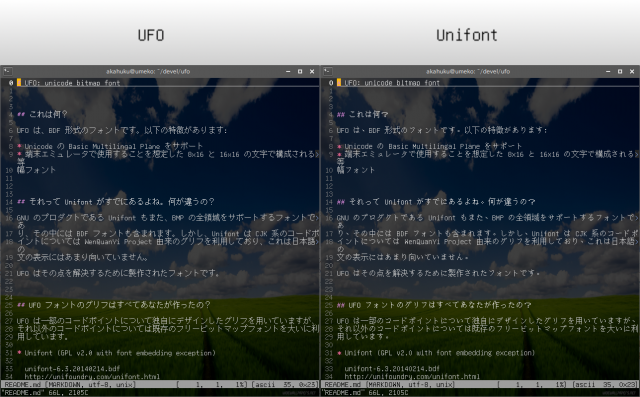
UAX#11: East Asian Width という、なんとも適当なドキュメントがある。
いわゆる全角・半角という概念を Unicode 上に持ってきて、どの文字が Wide でどの文字が Narrow か云々、というのを定義してたりしてなかったりする実に適当なドキュメントである。
まず幅についてのクラス分けをしている。
- Wide: 常に全角の字。「あ」とか「漢」とか
- Full width: 半角と全角両方ある字のうち、全角の方。全角の「A」とか
- Narrow: 常に半角の字
- Half width: 半角と全角両方ある字のうち、半角の方(この分け方だと U+0020-U+007F は Half width になる気がするが、実際にはそれらは Narrow となっている。Basic Latin は特別扱いなのかもしれない)
- Ambiguous: よくよく考えてみれば全角にする理由は特にないけれど、東アジアの野郎どもが彼らの文字セットに入れてたので、慣例的に全角になるような雰囲気の字。つまりこれは、東アジアの野郎の慣例を抜きにすれば別に半角でも構わない──よって、曖昧
- Neutral: 東アジアの野郎どもが知らない字
Unicode のすべてのコードポイントにこのクラスのいずれかを割り当てる。それにより、端末のような縦横のグリッドの中に文字を収めていくような表示デバイスについて、グリッドいくつ分を消費するのかの判断のもとになる、はずだった。Wide/Full width/Narrow/Half width については悩む必要はないのだが、問題は Ambiguous と Neutral なのだ。
Ambiguous な文字の幅の問題は、たとえば vim で「●」とかの表示が変なんですけど! → set ambiwidth=double しなさい的なお約束がググれば出てくるアレである。これについては、Unifont においては更に厄介な問題となっている。
いずれの端末エミュレータにしても、あるいは vim のようにアプリケーション側で Ambiguous な字をハンドリングするにしても、だいたいは A 属性の文字全体を半角として扱うか、それとも全角として扱うかの二者択一になると思う。ところがこれに対して Unifont では、半角のつもりの A 属性の字と全角のつもりのそれが混在しているのだった。たとえば U+2460、丸数字の1は Ambiguous 属性だが、Unifont はこれを全角幅としてデザインしている。一方、U+0391 からの Greek アルファベットもまた Ambiguous であり、そのグリフは半角幅である。
すなわち、端末で Unifont を使っている限り、Ambiguous な字の取り扱いを全角にしようが半角にしようが、その半分は常に正しく表示できない。
なんだこれ。どうしろってんだ。
次に Neutral な文字で、こちらはさらに輪をかけて混沌としている。
ぶっちゃけた話全角・半角の違いって、プロポーショナルフォントを描画できるデバイスとか、描画を自分で完全に制御できるプログラムではそれほど重要ではない。むしろ端末のような表示デバイスで「どう表示するか?」に直結してくる問題だと思うのだけど、冒頭の UAX #11 はどういうわけか端末に対する記述は全くない。「文字を幅によってクラス分けしてみたよ! やったね!」以上のことを何も教えてくれない。
なんとか判断してみるにしても、Neutral はつまるところ Neutral である。幅の情報は一切含んでいない。それを半角・全角のいずれかと判断するためのいずれの理由も見出すことはできない。とりあえず実際のところ、おそらく既存の端末エミュレータはそれを Narrow 文字として取り扱うと思う。それが楽そうなので。
一方、Unifont はどうなっているかというと、たとえば Devanagari の文字はすべて Neutral だが、なんとすべて Wide としてデザインしてあるのである。16 ピクセルでよく描いたなーと思わせる良いグリフなのだけど、しかし以上のような状況を勘案すると、今のところ既存の端末エミュレータの中のテキストエディタ上でそれを正しく表示したり編集したりはできないんじゃないかと思う。
えーと…なんだこれ。どうしろってんだ。