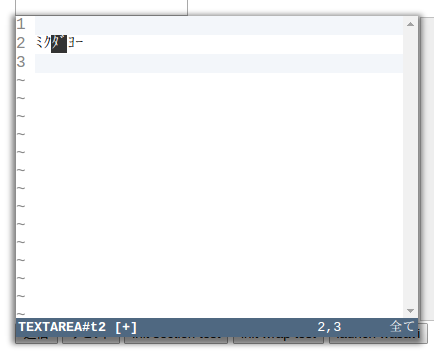
次に、[cci]f/F/t/T[/cci] コマンド。つまり [cci]motionNextWord()[/cci] と [cci]motionPrevWord()[/cci]。
これらのコマンドの本質的な部分では、特に書記素クラスタなどのことを考える必要は実はあまりない。キーボードから直接入力できる文字の中に結合文字が基本的にない。OS の digraph 機構等々を経由してもし入力できたとしても、コマンドは書記素クラスタの先頭文字との一致を判定するので、結合文字そのものにマッチすることがない。
これは不便といえば不便かもしれない。「Circumflex 付きの任意の文字をサーチしたい」などといった要件はないわけではないと思う。でもそういうのは [cci]/ ?[/cci] コマンドが担当するべきかなあ。微妙。
ただ、[cci]t/T[/cci] コマンドは入力された文字の位置へカーソルをおいた後 1 文字進めたり戻ったりする仕様なので、その時は 1 書記素クラス多分前後させねばならない。
次に、[cci]^/$[/cci] コマンド、つまり [cci]motionLineStart()[/cci] と [cci]motionLineEnd()[/cci] だが、これこそ書記素クラスタのことを考える必要は全くない。何を単位にしようが文字列の先頭と末尾は同じだ。
めんどくさいのは [cci]j/k[/cci] すなわち [cci]motionUpDown()[/cci] だ。